External Knowledge in LLMs
LLMs are trained on finite set of data. While it can answer wide variety of questions across multiple domain, it often fails to answer questions which are highly specific and out of its training context. Additionally, training LLMs from scratch for any new information is not possible like traditional models with fixed retraining frequency. This is because training LLMs are expensive, time consuming, requires training alchemy. Moreover, LLMs that depends only on their parameterised memory cannot be used to power real-time use-cases like synthesising news, summarising latest events, etc. Hence, it is extremely important to create systems around LLMs which can infuse external knowledge into LLMs quickly and in cost efficient manner. In this blog, we will first discuss different types of LLMs and what approaches can be used on these models to infuse external knowledge.
Stages of LLM Training
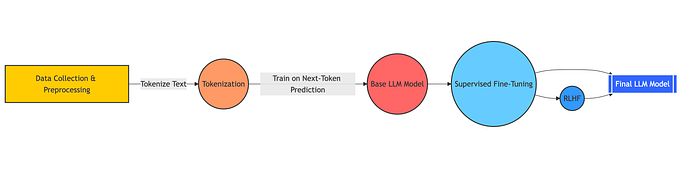
LLMs are trained in various stage which each stage generates a model which is used for different purposes.
- Unsupervised Pre-training: In this stage, the LLM is trained to predict next word using large amount of unstructured data, generally curated from open web. The output from this stage is “base” model which is generally used for generating embeddings, transfer learning and for further fine-tuning in next stage.
- Instruction Tuning: In this stage, the “base” model is fine-tuned to predict next work with high quality instruction following <prompt, response> pairs curated manually by humans. The output from this stage is “instruction tuned” model which can be used for zero shot / few shot prompting and instruction following tasks.
- Human Alignment: In this stage, multiple responses are sampled from instruction tuned models for a given prompt. The response are ranked in terms of their alignment with human response. Finally, this feedback is used to further fine-tune to instruction tuned model to make sure the model is aligned with human interest. The output from this stage is “aligned” model which is generally used for chat use-cases.

Stages of GPT training. Reward Modelling + RL can be thought of as human alignment stage. Recent methods like DPO can be used to created aligned model without explicit reward modelling.
Training in all these stages is conducted with limited data. Since no model can encompass the entire world’s knowledge, there’s a need to incorporate external knowledge. The external knowledge can be broadly transformed into two types:
- Unstructured Knowledge: Unstructured data is a collection of free form text across public or private data. For example, internal documents, news articles, information on the web, comments, etc.
- Structured Knowledge: Structured knowledge is defined for a specific task in a fixed format with well defined fields. For example: knowledge graph, sentiment classification, summarisation, comment toxicity classification, translation, etc. In all of these task, the data is represented by a set of well defined fields. For example, a dataset for comment toxicity classification with contains comment, and it’s toxicity ratings. The toxicity ratings will be in a fixed format either a ratings from 0–5 or classes like “highly toxic”, “moderately toxic” or “not toxic”
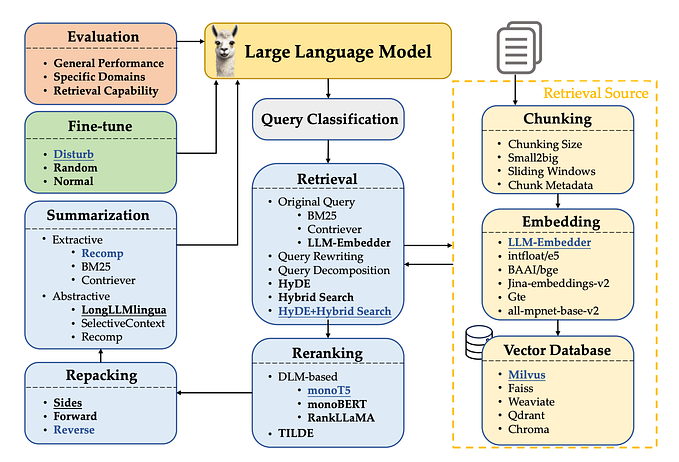
Methods
Let’s go over these methods one by one and discuss their challenges.
- Fine-Tuning: In this method, the all the parameters of the model model is retrained with next word prediction task over new data. This is generally carried out with lower learning rate to avoid catastrophic forgetting. Full model fine-tuning is expensive to perform and can lead to overfitting on small datasets due to large number of parameters. For multiple downstream tasks, it becomes harder to deploy multiple LLMs in production.
- LoRA Fine-Tuning: The idea for LoRA comes from reduction of weight updates (from fine-tuning) into lower dimension. During any fine-tuning, the initial weights w are transformed to w’ such that w’=w+Δw. LoRA decompose Δw into lower rank such that number of update parameters are reduced. This allows LLMs to learn from small data and allows for efficient deployment of multiple downstream models.
- Parameter Efficient Fine-Tuning (PEFT): PEFT are set of methods to fine-tune LLMs with less parameters. Some of the common methods are:
- Prompt Tuning: This method appends set of trainable soft tokens at different places in the prompt. The soft tokens are trained in continuous space with the new data. Deployment is easy as just new “tokens” (embeddings) needs to be appended with same underlying model.
- Prefix Tuning: This method adds soft prefixes (tokens) at every layer of the model, not just at the prompt. It uses additional MLP to generate these soft prefixes.
- P-Tuning: This is similar to prompt tuning but uses LSTM / MLP to generate soft tokens. The hypothesis being that it is more convenient to model dependency between embeddings using a model instead of training embeddings directly.
- P-Tuning V2, Llama Adaptor - Retrieval-Augmented Generation (RAG): RAG infuses external knowledge into the LLMs by retrieving query (question) relevant information into the prompt. RAG thus required an additional indexing pipeline which indexes the external data. This indexing can be traditional search index or a modern MIPS based embedding index. One indexing is complete and a query is issued, the documents (in context of search engine) related to the query is fetched from the index and added into LLMs prompt to generated the answer using a generation model.
RAG requires you to maintain a additional retrieval system whose quality needs to be adequate to fetch relevant documents. Additional, due to limited input and output context window length, it might not be always possible to collect all relevant information related to topic in single prompt. In such situation, parameterised condensation of external knowledge is preferred. - Prompt Engineering (Zero Shot / Few Shot): A common way to infused small amount of external information is through writing better quality prompts. The prompts could contains examples, clear task instructions and relevant passages or documents. You can learn more about prompt engineering here
Choosing Right Method?
The section above summarises common methods to infuse external knowledge into LLMs. The two common themes from the above can be seen as knowledge in parameters and knowledge in prompts. The table below presents list of methods to train different models for different types of knowledge for different use-cases.

Closing
In this blog, we discussed methods for infusing external information into LLMs. The common theme across all methods are knowledge in parameters and knowledge in prompt. While knowledge in parameters is helpful for building domain-specific and task specific models and for reducing cost, knowledge is prompt is helpful for quick infusion of small information and generating grounded responses. For some use-cases, mix of both is required. For example when building a Q/A system for legal use-case, one might need to first fine tune a base LLM with legal specific unstructured data and then use RAG setup for grounding response.
Additionally, there are other techniques to generate synthetic data by transforming your data into another format. For example, you can generate structured knowledge from unstructured knowledge by transforming it using a instruction tuned LLM like GPT-4 or Gemini.
Empirically, Ovadia et al. reports that, for infusion of unstructured information, RAG outperforms unsupervised fine-tuning. LLMs struggle with learning new facts through fine-tuning. Training with multiple variations of the same fact helps.
Thanks for reading. Subscribe to get notified with more such content.